How Web 3.0 will impact higher education
The birth of the internet is considered to be 1 January 1983 – since its inception, the internet has rapidly evolved and spread across the world to impact all aspects of our lives. How will its current development phase, labelled as Web 3.0, have an impact on higher education in particular?
Web 3.0 overview
Web 3.0 is sometimes referred to as the ‘semantic web’, ‘3D web’ or ‘spatial web’. It is about using new technology to add meaning to content and developing methods to interact with our environment. In the semantic web, content will find you. Rather than you seeking information based on, say, keywords, your activities and interests will determine how information finds you and the format you need, and display it within your preferred channel.
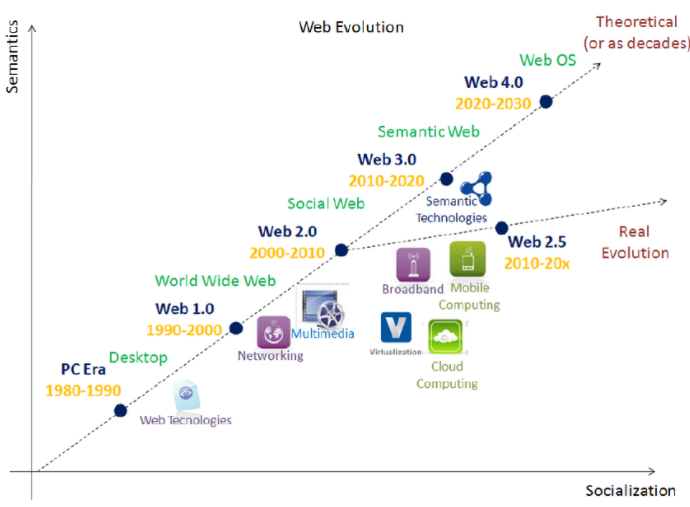
Web 3.0 builds on earlier phases:
- Web 1.0 can be considered as ‘read only’ – information is published to a website where users can read and search for information, but there is no opportunity to easily share or interact with it.
- Web 2.0 can be thought of as ‘read and write’ – it provides social networking tools such as blogs and wikis. It focuses on its ability to bring people together, share knowledge and facilitate communication. It also facilitates collaborative learning and teamwork.
The problem with Web 1.0 and Web 2.0 is that information is chaotic and unstructured, limiting the ability to retrieve relevant and accurate information. Web 3.0 promises to solve these problems.
Web 3.0 technologies
The following is a brief summary of some of the key developments that will change the way users find information.
Artificial intelligence
Artificial intelligence is self-learning programmes that can learn and evolve on their own, for example, track the habits of users and provide search results that suit their preferences.
Personalisation
Users will be able to enter their preferences and interests, and the computer will customise and provide information that fit these criteria – user profiles will function like a virtual avatar that represents them and their interests online.
Internet of things
The internet of things is the connection of everyday devices to the internet. For example, sensor-equipped and networked devices such as office equipment, printers and vehicles. It means that users will be able to connect to the internet and manage information from anywhere.
Virtualisation
Users can interact with their environment using virtual environments and augmented reality – search results are not restricted to text-only inputs – you can search by inputs via 3D objects or images. The physical world can be interacted with interfaces such as smart glasses and voice where the digital and physical layers are merged.
Decentralised computing
With Web 3.0, computing power is not confined to a few central servers that provide content. Instead, computing power is shared across multiple servers. An example of this is blockchain technologies where information is distributed across many devices. This means that information can be held very securely and is not dependent on a single provider.
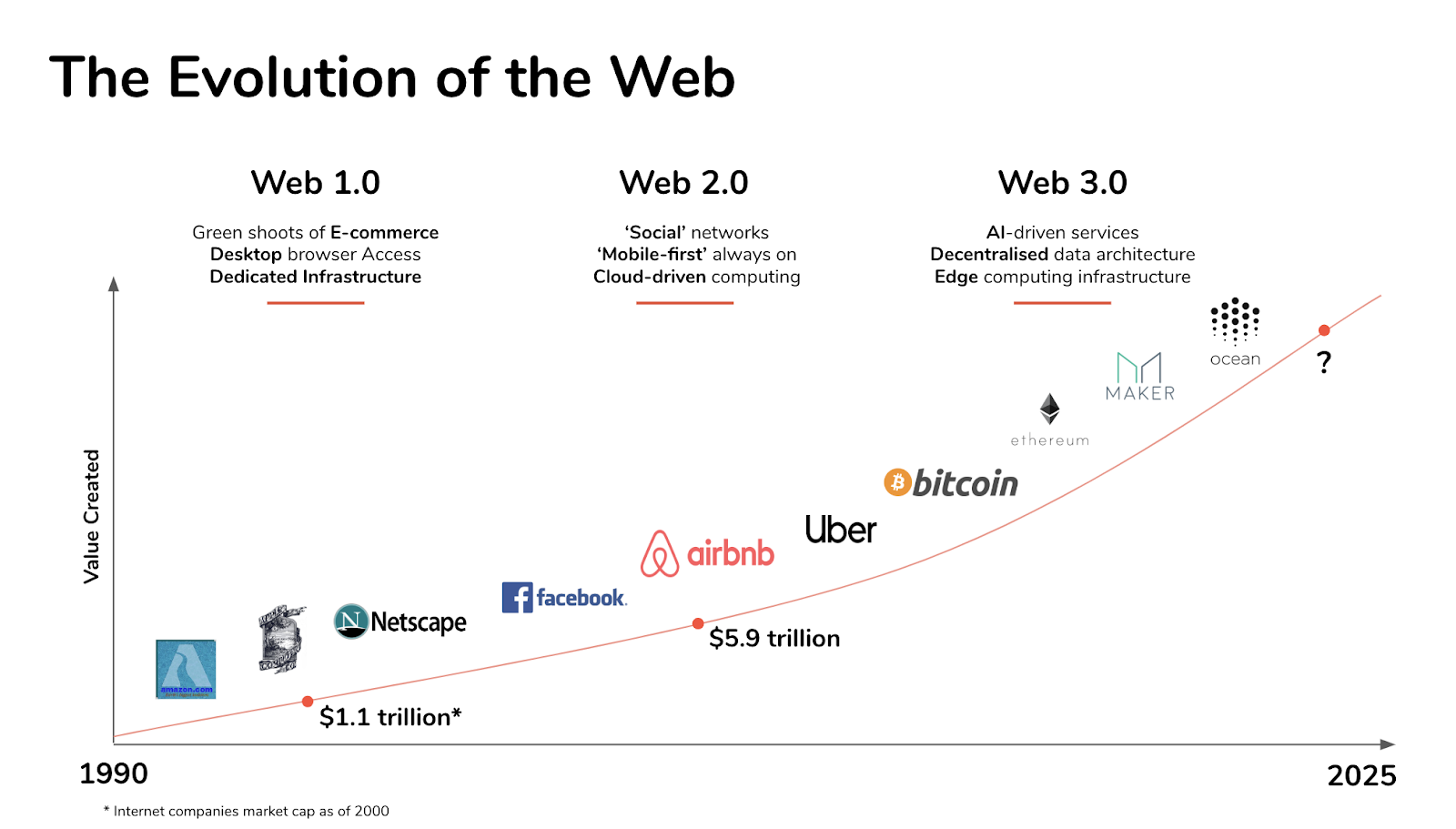
The future of Web 3.0
Today’s web browsers have limited capacity for discovering connections among pieces of information that might be useful or valuable. A standard Google search yields hundreds of results, many of which are irrelevant or marginally relevant.
With Web 3.0, standards will create structured online content using tags or fields that enable a browser to identify and understand the meaning of information more readily. This requires the translation of online information into ‘micro content’.
For this to work, content managers will need to add metadata descriptions that give meaning to website content and describe the structure of existing knowledge about it. As a result, content will be more efficiently searchable and interconnected. There are various standards that can be used to tag data such as RDFa and JSON-LD.
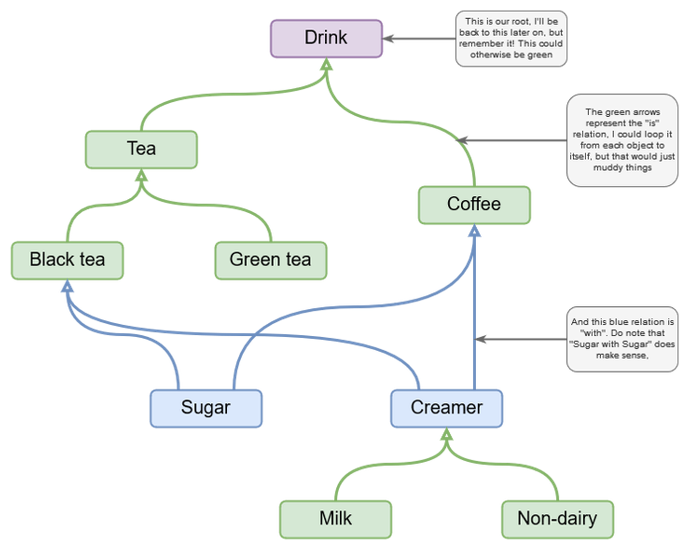
As well as tagging content there are various approaches to creating relationships between content – known as ontologies. Protégé, developed by Stanford University, is a free ontology editor that can create these connections use the OWL 2 Web Ontology Language .
A simple example of an ontology is shown in the figure below – in this case it shows how meaning can be given to content related to different types of drink.
Web 3.0 will have natural language search capabilities that will enable users to ask a complete question rather than phrases in isolation. At the moment, search engines train us to become good keyword searchers – we dumb down our intelligence so that it will be natural for a computer. The big shift will be to have a computer handle expressions that are natural for the human.
Web 3.0 and education – benefits
With Web 3.0, the ability to find information more easily and quickly has a number of benefits, but also disadvantages. First, the benefits:
- Reduced expense as machines will be internet-connected and provide access to knowledge.
- Changes in teaching – teachers will be able to develop engaging and more complex assignments that are supported by a variety of resources. Students will develop more independence that will free teachers to tutor individuals or small groups. There will be a shift from students consuming teacher-provided content to student creation of content.
- Learning – students will spend less time gathering and integrating knowledge. They will be able to learn anywhere and anytime if they have access to the internet.
- Knowledge construction – search engines will produce a report that draws from many sources. The report will also compare and contrast the information presented and allude to different arguments as well as alert users to related topics and resources.
- Smart searches – customised search capabilities will yield only information tailored to the user, preventing frustration and saving time. Search engines will include lecture notes, resources, videos, blog articles etc.
- Personal learning network maintenance – personal learning agents will search for information related to a learning goal and only report relevant information. Location-based services will send appropriate information.
- Personal educational administration – use semantic web to describe courses and degrees so that it will be easy to transfer credits, and students can easily determine universities that will give them the knowledge they seek. E-learning and just-in-time learning become commonplace. People can collaborate and interact with dispersed individuals. Educational content can be used and reused with requiring permission.
Web 3.0 and education – issues
- Impact on student learning – students spend less time gathering information, but these are important skills. Presenting students with information that has already been synthesised eliminates the need for critical thinking, evaluation and argument. For example, when calculators were introduced it was expected to free students from manual calculations so they could concentrate on the solution. This is true for students working on advanced levels of subject knowledge, but if introduced too soon, they impede the development of basic mathematical skills.
- Tagging information – who is going to tag content and add additional coding to web pages? This takes significant time and resource.
- Developer bias – it is likely that developer bias and perspective will go into tagging information. Even subtle tweaks could eliminate some relevant information or include information that is important only to the developer.
- Information security and privacy – user preferences and online behaviour can be inaccurately interpreted and used to filter their information in ways the users did not intend.
- Censorship and privacy issues – a large amount of personal data will be on the internet. Data scraping means data from web pages can be extracted and used for articles that reach completely different conclusions than intended by the author and without giving credit to the author. If content is not coded, it may be ignored by Web 3.0 browsers and not become part of the content knowledge of a particular subject area.
Conclusion
Web 3.0 promises to allow users to find information and connect with it in more meaningful and efficient ways, but at what cost to the way students develop skills in researching and understanding information for themselves? Being aware of the pros and cons of Web 3.0 is the starting point to understand how we can take advantage of the benefits while guarding against the potential disadvantages of deskilling students and reducing their ability to discern the value of information for themselves.