From strings to things
Website searches have the potential to be a much richer experience than just finding content that matches the search term (string). Google has been providing ‘rich snippets’ since 2009 to describe people, provide reviews, news, events and other content that is associated with the query (things).
How can we make University website content available to search engines so it can be used in this way? For a good overview of this topic, see a video on how to use Schema.org to create and add structured data to your website.
Rich snippets
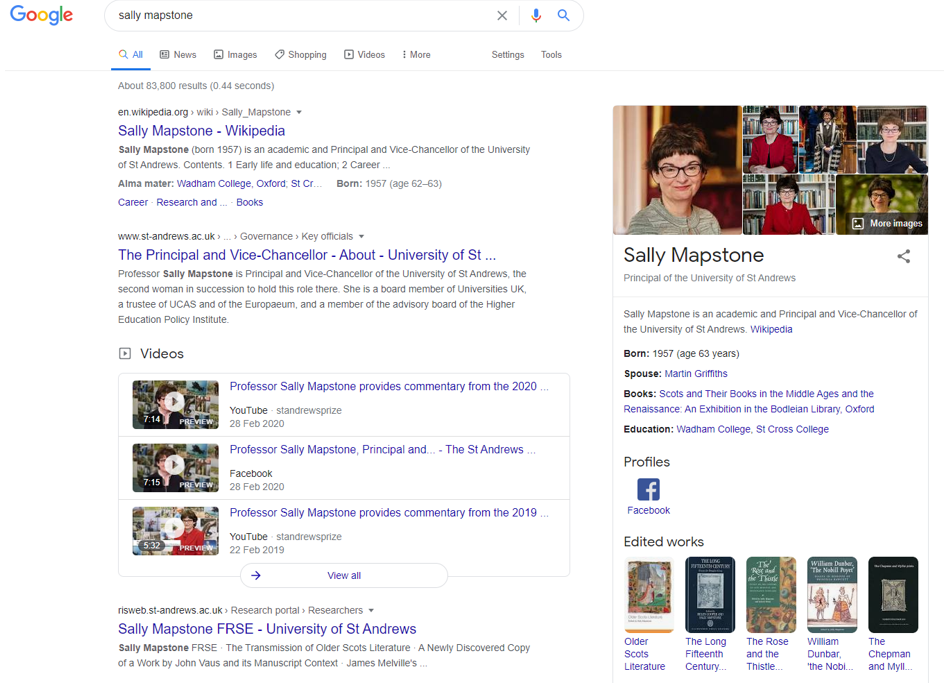
Here is an example of what Google returns when a search is carried out on Sally Mapstone. The search results includes videos and published books. It is more than just a link to an entry in Wikipedia. How does Google do this?
Schema.org
Search engines need to rely on a standard way of indexing content so that they can make sense of it. A way to do this is to add hidden information in the code of the page. This hidden information (metadata, or markup) can be defined by a number of different standards.
A popular set of standards is provided by schema.org. The schema.org website defines many ways to structure content. Once the relevant standard has been found, there are three ways to add this.
Consider the following HTML that provides information about an event.
<h1>Musée Marmottan Monet</h1>
<div>It's a museum of Impressionism and French art.</div>
<div>It is hosting Monet's exibit: "Peindre l'impossible". Start date: September 15 2016 End date: January 22 2017</div>
Microdata
Here is the same HTML content using the schema.org microdata approach:
<div itemscope itemtype="https://schema.org/TouristAttraction">
<h1><span itemprop="name">Musée Marmottan Monet</span></h1>
<div>
<span itemprop="description">It's a museum of Impressionism and French art.</span>
</div>
<div itemprop="event" itemscope itemtype="https://schema.org/Event">It is hosting
<span itemprop="about">Monet</span>'s exibit:
<span itemprop="name">"Peindre l'impossible"</span>.
<meta itemprop="startDate" content="2016-09-15" />Start date: September 15 2016
<meta itemprop="endDate" content="2017-01-22" />End date: January 22 2017
</div>
</div>
RDFa
This time with the RDFa (Resource Description Framework in Attributes) method:
<div vocab="https://schema.org/" typeof="TouristAttraction">
<h1><span property="name">Musée Marmottan Monet</span></h1>
<div>
<span property="description">It's a museum of Impressionism and French art.</span>
</div>
<div property="event" typeof="Event">It is hosting
<span property="about">Monet</span>'s exibit:
<span property="name">"Peindre l'impossible"</span>.
<meta property="startDate" content="2016-10-01" />Start date: September 15 2016
<meta property="endDate" content="2017-02-05" />End date: January 22 2017
</div>
</div>JSON-LD
Finally, the other method is JSON-LD (JavaScript Object Notation for Linked Data). This has the advantage of being completely separate from the source HTML and therefore doesn’t risk changing the appearance of a web page. It is also the method that Google prefer to use. The code is typically placed in the header of a web page. For example:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "TouristAttraction",
"name": "Musée Marmottan Monet",
"description": "It's a museum of Impressionism and French art.",
"event": {
"@type": "Event",
"about": ["Monet"],
"name": "Peindre l'impossible",
"startDate": "2016-09-15",
"endDate": "2017-01-22"
}
}
</script>Schema. org and the University of St Andrews
We are using the JSON-LD method to add metadata using the schema.org standard to the University home page and to news items. For the University home page we are publishing this via T4, while news items are using the Schema Press plugin on WordPress.
On the University home page we have the following code that provides information about the associated social media accounts as well as contact details:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "CollegeOrUniversity",
"name": "University of St Andrews",
"logo": "https://www.st-andrews.ac.uk/php/meta/university-of-st-andrews-logo.png",
"url": "https://www.st-andrews.ac.uk",
"telephone": "+441334476161",
"sameAs": ["https://twitter.com/univofstandrews/","https://www.facebook.com/uniofsta","https://www.youtube.com/uofstandrews","https://www.instagram.com/uniofstandrews"],
"address": {
"@type": "PostalAddress",
"streetAddress": "College Gate",
"addressLocality": "St Andrews",
"postalCode": "KY16 9AJ",
"addressCountry": "United Kingdom"
}
}
</script>Creating meta data
The Schema.org website can be overwhelming, so what is this best way to get started with adding metadata to a web page?
Steal Our JSON-LD
The Steal Our JSON-LD website provides pre-defined recipes for common situations. The code examples can be copied and then easily modified to suit your content.
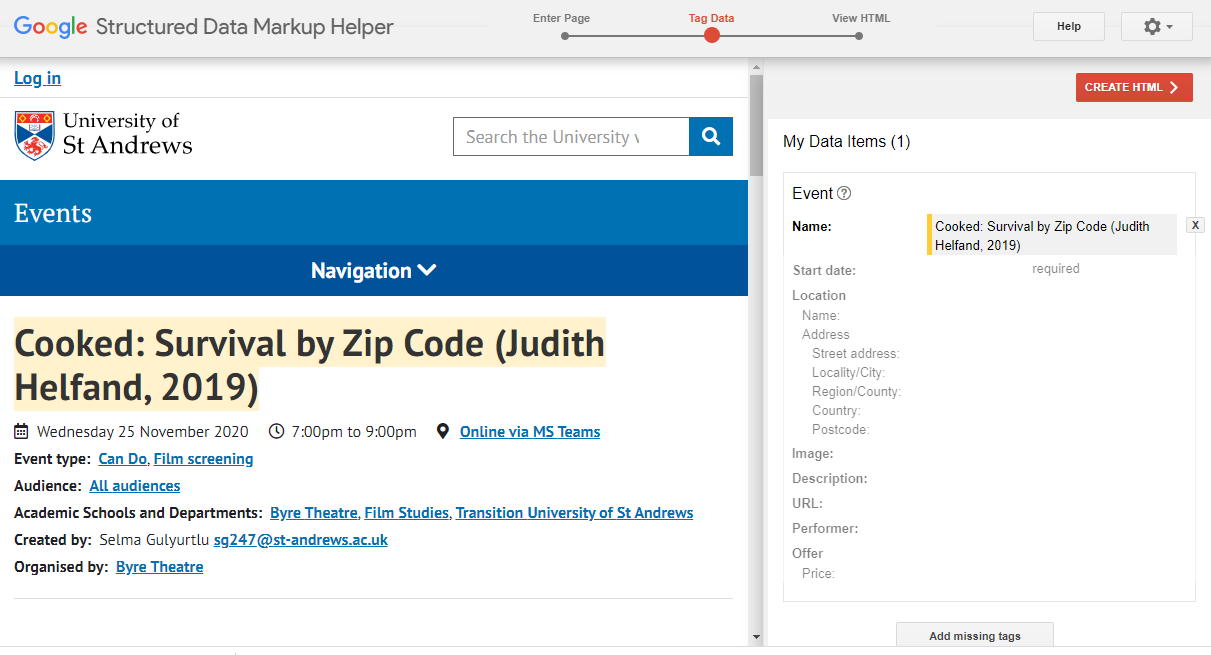
Google markup helper
Google provide an easy way to create markup using their structured data markup helper. The helper website involves highlighting content and then assigning it to a tag. For example, in the following event, the title was highlighted and than attributed to the name tag. Once tags have been assigned, the JSON-LD markup is created for you.
<!-- JSON-LD markup generated by Google Structured Data Markup Helper. -->
<script type="application/ld+json">
{
"@context" : "http://schema.org",
"@type" : "Event",
"name" : "Cooked: Survival by Zip Code (Judith Helfand, 2019)" }
</script>Testing metadata
It is important to test the hidden code on the page. Google provide a Rich Results Test site. The test will confirm whether it has found the metadata or not and give a report on any issues it has encountered.
Monitoring
Once the code has been verified it is important to monitor how it is being used. This can be found via Google Search Console. It is found under search results > search appearance > rich results.
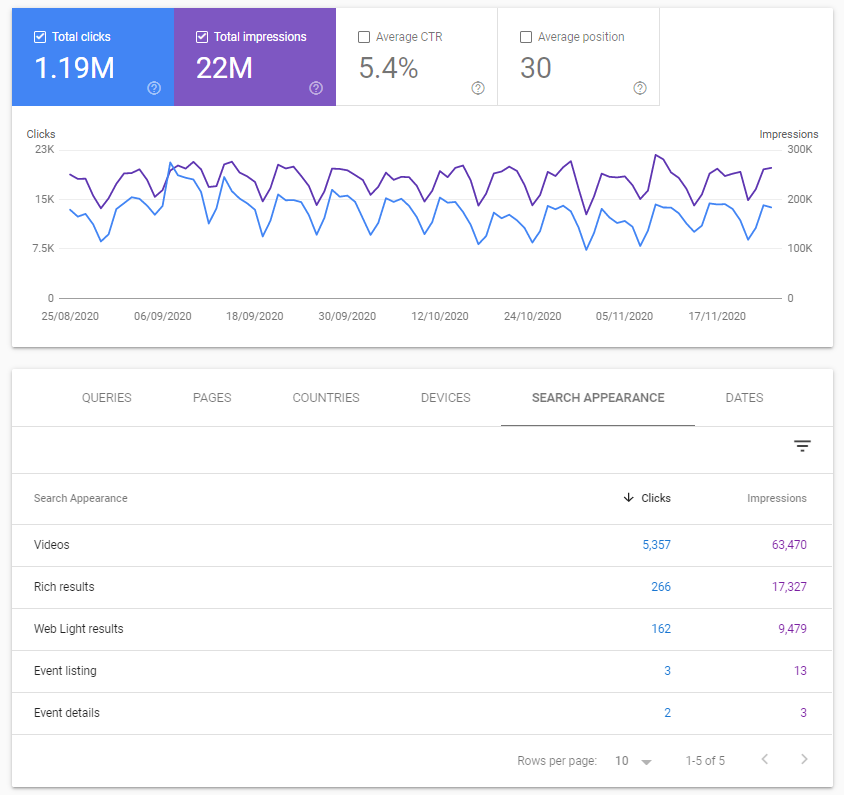
The search console provides details on what users are search for and how the results are being returned. For further details see information provided by Google.
The future
Adding metadata to a web page can help search engines provide a richer experience to users when trying to find information. We are going to explore how we can use Funnelback (the University search engine) to improve the search experience by bringing associated information about staff, events, research, policies and news into one place.